Imagine sitting in a room with a few hundred boxes. Each box contains a few dozen to a few hundred photos. Each photo has a number, but no name or anything. You may only open one box at a time. Image you try to find one particular photo.
Does this sound vaguely familiar? This is basically how image storage works under any operating system I know today. In this post I will try to outline some of the problems I see with data handling in general in today’s operating systems and a few ideas on how I think things should work in the future (often using examples from huge photo databases as this is the example where I have experienced current shortcomings the most). I invite you to read it regardless of your background, be it that of a it "tech-savvy" or a normal user who just wants to get some work done. Some of the things I write here may be hard to understand for people who are not used to computer-speech, but I will try to remain generally understandable and use many examples etc. Please use the comment feature at the bottom to tell me your opinion on the matter - I’m very interested in other peoples comments on all of this!
<h2>Problems </h2>
When "modern" filesystems were invented, noone imagined average users to have gigabytes of relevant data, stored in several thousand files. Here is a short list of what I think have become problems by now:
<ul> <li>Strictly hierarchical classification. Hierarchical classification works fine for things that are of primary interest for the computer (like its startup-files etc.) but are quite the opposite of how humans would describe the data. Compare "This is a photo of my aunt that I took last christmas" to "The path of this file is C:\photos\Winter2005\Auntie.jpg". (Of course it might as well be "C:\photos\CANON786\IMG8479.jpg").</li> <li>A file belongs to exactly one folder. In reality, a file usually belongs to more than one category or "folder". In the above example, the following might be reasonable categories: family, christmas, parties, winter, maybe something more personal like funny or nice photo or have to show chrissy. When storing a file in a folder you have to decide for exactly one of those - you cannot mark it to belong to several folders. (Another example is music - I once tried to sort my mp3 by genre, but it is of course impossible to assign a song, let alone a whole album or band, to only one genre).</li> <li>No consistent metadata support. Digital cameras store metadata nowadays, but they do so inside the files. This is comparable to having detailed information on each photo like the exact time it was taken, what camera was used etc, but written on the back of the photo - pretty useless if you try to search it. A central index would be very useful, but is not easily possible today.</li> <li>Datastructures are opaque. Software developers today seem to think that interoperability of their data is a bad thing. After all, if your e-mail program would store your e-mails in a format you could easily load it into another program - and their precious piece of software were suddenly exchangeable! Well, yes, but it would also be possible to write software that links data together - not on the level of what we know as a file today (an obscure, unreadable piece of binary data), but on an "atomic" level. E.g. each contact in your e-mail program could be a "atomic data junk", as could be a function/class in source code or photos and concurrent text-flows in a dtp file. If it were stored in a readable way (e.g. as XML with a schema) other programs could easily use it.</li> <li>Filesystems have no versioning support (at least none that is exposed to the user). When you overwrite a file, your old version is gone. Hopefully you have a backup somewhere. This is not necessary - the files you usually overwrite a lot are textfiles or office documents or something like it for which it would be cheap to store hundreds of versions. Videos or photos are usually not edited a lot and if you would have to you could mark them as "not versioned" or specify which edits to mark as a new version.</li> <li>General attitude. Filesystems today approach the user with the attitude of "I work this way, so use me this way". But users are very different, and filesystems should be designed to be pluggable. A photographer has very different workflows than does a programmer or a scientist or a video cutter. </li> </ul>
<h2>Some suggestions </h2>
From the descriptions above I have come to a few requirements that I would want from a modern filesystem:
<ul> <li>Hierarchical tagging of content. Hierarchies can be very useful, but only if it’s easy <div class="image"> 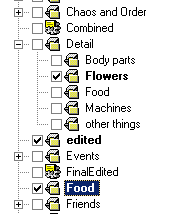 to add content to many places in the hierarchy with very few clicks/keystrokes. I personally think that hierarchical tagging, where you define a hierarchy as in a filesystem with folders - but can add something to as many folders as you like - is better than simply free tagging where you just write keywords, because this is prone to typos and inconsistencies. It works reasonably well for things like delicious where there are thousands of users indexing the same set of data, but I think it wouldn’t work nearly as well for filesystems where you are the only person indexing the data. IMatch, a program that is specially designed to manage large amounts of photos, allows you to categorize photos by tagging them hierarchically. See the screenshot at the side for an example on how this looks like. </div></li> <li>Metadata that is centrally indexed (and described using open standards like XML w. Schemas). If Metadata were available in a generic way and would be indexed regularly by the operating system it would be easily possible to search it. </li> <li>Fuzzy search. A search should consist of several, extensible modules that give a rating on how close each item matches the constraints of the user (e.g. easy stuff like time/date, filename etc. but also more advanced things like visual similarity, beats per minute …). Search results should be easily made persistent, so that they work like a folder of shortcuts/links would today. If metadata were indexed this would be rather easy to do.</li> <li>Rich versioning. Just imagine what it would be like to be able to not only go back to each version of a file you created and saved, but also to trace branches/merges of files. E.g. my workflow with photos is like this: I shoot a photo, usually in RAW, which is data as recorded by the camera with no manipulation by the cameras software. It is pretty much impossible to add any metadata to these fileformats. So first of all, I usually make a few edits to the photo (like cropping and sometimes basic color correction) and add a description. This already creates a new file that, currently, is totally unrelated with the original file (at this point - if you don’t use precaution - it is already impossible to sort your images correctly by time/date as shot because the time/date of the original image has not been preserved) . If I decide later on that some of my edits were off (e.g. the cropping was too tight) I have to search for the original picture and apply all the edits again and add the description again. The normal flow would now be that I might want to do some more advanced edits like remove a few pimples and save it as a new file. Then I would want to put it online so I create yet another, smaller, compressed version of the image, but maybe I also want it printed, so I create another file with the correct color-profiles that my lab needs and in high resolution. Each time I have to know (e.g. by not changing the filename) which image came from which one. Imagine just being able to let the computer display a tree to you that shows you which file was the original, when it was edited, which files resulted and where branches were made (several copies that came from one common ancestor file but were changed in different ways).</li> <li>Part of the core operating system. All of this has to be implemented so centrally that it works automagically for each program. If this is something that you have to use a special program for that is not integrated with others this renders the whole system rather useless.</li><li>Good software libraries. Of course there would have to be a decent implementation of all this that is accessible at both a low, C++ish level and a higher level for scripting languages etc.
to add content to many places in the hierarchy with very few clicks/keystrokes. I personally think that hierarchical tagging, where you define a hierarchy as in a filesystem with folders - but can add something to as many folders as you like - is better than simply free tagging where you just write keywords, because this is prone to typos and inconsistencies. It works reasonably well for things like delicious where there are thousands of users indexing the same set of data, but I think it wouldn’t work nearly as well for filesystems where you are the only person indexing the data. IMatch, a program that is specially designed to manage large amounts of photos, allows you to categorize photos by tagging them hierarchically. See the screenshot at the side for an example on how this looks like. </div></li> <li>Metadata that is centrally indexed (and described using open standards like XML w. Schemas). If Metadata were available in a generic way and would be indexed regularly by the operating system it would be easily possible to search it. </li> <li>Fuzzy search. A search should consist of several, extensible modules that give a rating on how close each item matches the constraints of the user (e.g. easy stuff like time/date, filename etc. but also more advanced things like visual similarity, beats per minute …). Search results should be easily made persistent, so that they work like a folder of shortcuts/links would today. If metadata were indexed this would be rather easy to do.</li> <li>Rich versioning. Just imagine what it would be like to be able to not only go back to each version of a file you created and saved, but also to trace branches/merges of files. E.g. my workflow with photos is like this: I shoot a photo, usually in RAW, which is data as recorded by the camera with no manipulation by the cameras software. It is pretty much impossible to add any metadata to these fileformats. So first of all, I usually make a few edits to the photo (like cropping and sometimes basic color correction) and add a description. This already creates a new file that, currently, is totally unrelated with the original file (at this point - if you don’t use precaution - it is already impossible to sort your images correctly by time/date as shot because the time/date of the original image has not been preserved) . If I decide later on that some of my edits were off (e.g. the cropping was too tight) I have to search for the original picture and apply all the edits again and add the description again. The normal flow would now be that I might want to do some more advanced edits like remove a few pimples and save it as a new file. Then I would want to put it online so I create yet another, smaller, compressed version of the image, but maybe I also want it printed, so I create another file with the correct color-profiles that my lab needs and in high resolution. Each time I have to know (e.g. by not changing the filename) which image came from which one. Imagine just being able to let the computer display a tree to you that shows you which file was the original, when it was edited, which files resulted and where branches were made (several copies that came from one common ancestor file but were changed in different ways).</li> <li>Part of the core operating system. All of this has to be implemented so centrally that it works automagically for each program. If this is something that you have to use a special program for that is not integrated with others this renders the whole system rather useless.</li><li>Good software libraries. Of course there would have to be a decent implementation of all this that is accessible at both a low, C++ish level and a higher level for scripting languages etc.
</li> </ul>
<h2>Conclusion
</h2> <p>When I first heard of WinFS, the new filesystem that was originally planned for Longhorn, the next big release of the windows operating system, I was very excited about it. It sounded like finally someone would get a lot of it right and on top of this even have the weight in the market to force software developers to reasonably implement these new features. But it seems that Microsoft, in what seems to me to be one of their biggest strategical mistakes in recent times, abandoned WinFS for longhorn, planning to ship it maybe by 2008, maybe later, maybe not at all.
There are other attempts to solve these problems - Gnome Storage seems to be an attempt in this direction, and Apple seems to implement some of the search-features I describe above with Spotlight in their latest release of OSX. There are also special-case programs that solve quite a few of the problems for a specific filetype, like IMatch does for photos. Yet I have my doubts whether any of those will solve all of my (and I think computer users in general) problems "once and for all" - at least until some other challenge like non-stop videorecordings of peoples lives come around in a few decades.
As a last note: I have thought, occasionally, of hacking it - that is, to create the infrastructure for versioning, metadata storage and indexing etc and rewrite the standard open/save dialogs of the operating system. This, I think, would be both great and totally crazy. If you think this is feasibly, please, do let me know - I might be tempted to start such an effort - I think the sanity of computer users worldwide depends on the solution of at least a few of the problems I outlined above.
</p>
How we will be crushed by terrabytes of data
July 3, 2005